
Using employee text analytics to drive business outcomes

FIG 1: Examples of business questions that can be answered using employee text analysis (Source: Andrew Marritt, Organization View)
According to an article published earlier this year by Bernard Marr, 90% of the world’s data was generated in the last two years alone. Much of this data is unstructured data (mostly text but also images, video etc), which remains largely untapped by the majority of organisations especially when it comes to HR and people data.
Given the opportunities offered by ‘text analytics’, it is not surprising that people analytics teams and HR leaders are looking for ways to utilise this data to support their work.
One of the leading experts on text analytics from a people data perspective is Andrew Marritt, who has worked in the people analytics space for more than ten years, is a popular speaker on the conference circuit and is the Founder and CEO of Organization View, a people analytics company based in Switzerland. His Workometry product is being used by a growing number of companies to gain insights from employee text that drive business and people outcomes.
I spent some time with Andrew recently to discuss the opportunities afforded through text analytics, examples of case studies and recommendations for HR practitioners and people analytics teams.
1. ANDREW, WELCOME TO MYHRFUTURE, FIRSTLY, PLEASE CAN YOU PROVIDE A DEFINITION OF TEXT ANALYTICS?
Text analytics is the application of algorithms to process text information. When people talk about an explosion of data the growth is mostly in unstructured data - text, images, audio, video - not classical ‘numbers’ in databases. For firms probably the most common type of unstructured data is text.
With text analytics what we are doing is changing this qualitative, unstructured data to quantitative structured data. Once we have done this we can apply all sorts of statistical or machine learning analysis to it.
There are two general types of quantification that we do:
Coding or classifying the text which produces count data
Scoring the text – e.g. sentiment or emotion analysis - where we get a probability or score.
2. WHY IS THE USE OF TEXT ANALYTICS BY COMPANIES RISING?
Text analysis offers huge opportunities for firms. Firstly, in most instances text data has not been analysed. It tends to be really rich data and given it hasn’t been analysed there is a lot of potential insight to be found. Secondly, we can contrast this with what can still be done with traditional quantitative data. In many instances this has already been analysed numerous times and analysts are typically getting decreasing marginal returns. Third, as I mentioned earlier, text represents by far the largest source of data in most businesses and is also probably the richest.
3. WHAT ARE SOME OF THE USES OF TEXT ANALYTICS IN RELATION TO HR AND PEOPLE ANALYTICS?
HR has a lot of text. I think it’s worth thinking of text analytics on two levels:
What insight can you get from structuring the data?
If you have the data in a structured manner, what can you do with it?
The type of data we see most of the time comes from some sort of questionnaire. Only about 30% of the questions we see from surveys are typical ‘engagement’ questions. About 50% of questions ask employees about business challenges - so called Employee Voice - the rest are topics that HR departments care about such as performance management, manager effectiveness or diversity.
Outside survey data we see quite a lot of interest in performance management system data. We’ve done analysis of 360° data to look for differences in gender-related issues and analysis of objectives to see how top-level initiatives are being cascaded across the organisation. Increasingly we’re looking at development needs to see if firms can understand what employees are likely to want to have from a training perspective. Can they optimise the availability of training courses, so they’re offered close to the demand (reducing travel expenses)? Can we build a prediction engine to recommend courses before somebody logs in to the training catalogue?
Finally, there are lots of other places where text is being generated in HR departments. We’re doing an analysis of requests to / from a HR Helpdesk identifying patterns in a much more granular manner than could ever be understood with structured data capture. This information will hopefully drive a range of performance improvement changes improving service and reducing cost.
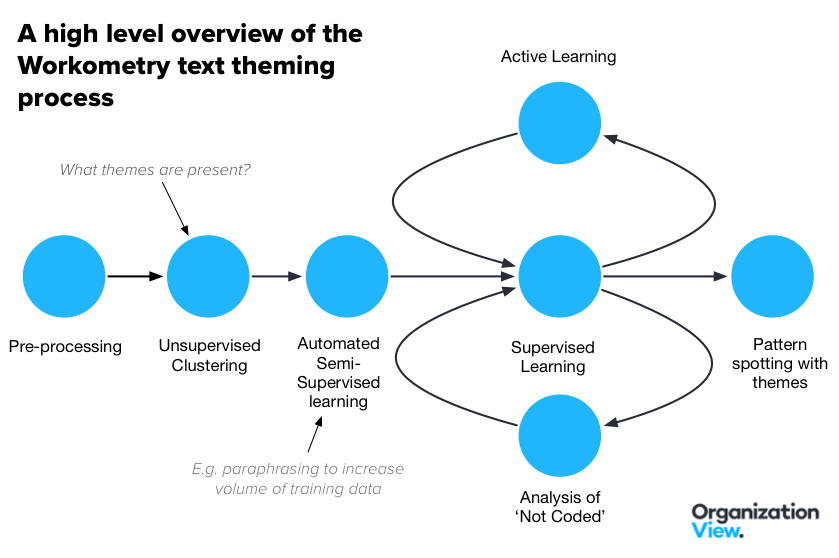
FIG 2: Overview of how Workometry themes text (Source: Andrew Marritt, Organization View)
4. WHAT ARE THE KEY CHALLENGES HR/PEOPLE ANALYTICS TEAMS NEED TO OVERCOME IN RELATION TO TEXT ANALYTICS?
The biggest challenge is the distance that you need to overcome before it can really become useful.
Our view is that the most important aspect of good analysis is context. This includes the requirement that the text needs to be analysed in the context of the question asked. It also needs to be understood in the context of the organisation plus it also needs to be understand in the context of what else people are talking about.
The common way of analysing text is to identify topics – e.g. communication or compensation. However, our experience is that this is rarely good enough to be useful. We believe that the data needs categorising down to a level where the label of the theme itself is a good answer to the question. So, communication could be ‘more transparent communication’ or ‘more frequent leadership communication’, ‘better inter-departmental communication’, ‘less electronic communication’ or even ‘less communication at the weekend’.
Another big challenge is that every organisation has its own language. Some of the time this manifests itself in an extensive use of acronyms - we used to have a part of the intranet defining many of the common ones when I was at Reuters. Other times it can be the way words are used inside the firm. One client’s managers talk about wanting to increase payroll when most other firms would describe the same thing as wanting to increase headcount. Our experience is there is always a significant improvement to be made by building firm-level models, so the terminology can be learnt.
Finally, great models will work well for one question but rarely are generalisable. Employees rarely write in sentences and they expect you to interpret their answer in the context of the question that was asked. The exact same text can have very different meanings depending on the question. We doubt that the sort of text analysis used in some HR technologies will be able to generalise.
Of course, I haven’t even mentioned the ’normal’ issues with data such as the time taken to clean and pre-process the data. This can be enormously demanding with text. Identifying which parts of a document to look for the relevant data - so called zoning - is something that we don’t focus on but would be essential if you want to read a CV for example.
5. PLEASE CAN YOU PROVIDE SOME EXAMPLES OF HOW ORGANISATIONS HAVE USED EMPLOYEE TEXT
Let’s take two specific examples, both of which had significant value.
One came from a retail client who was doing a regular pulse survey. In one quarter we saw a huge spike in employees talking about the music that was played in store. We could see that these employees were also more likely to be talking about customer complaints. The people who had made the comments were significantly more likely to be engaged than the average employee, but they also were talking about the company being out-of-date and management not listening.
Looking at a few of their comments it was obvious what had happened. In a search for cost savings there had been a decision to replace the in-store music for music with a lower licensing cost. As soon as the management saw the comments they reversed the decision.
The next month we saw a lot of comments about the music again, but this time it was employees thanking managers for changing the music and for listening.
Another example relates to a new CEO for a global firm. In his first message to staff he announced his intention to spend the first few months reviewing the business and invited all employees to let him know what they thought he should address. He got thousands of messages in many different languages.
We were brought in by the head of strategy to do an analysis on this feedback. One of the things that we identified was a theme about poor contracts / projects. When we linked the data to the organisational structure we realised that the majority of these comments were coming from a small part of the IT organisation. It turned out that there was a contract with a big external firm - tens of millions of dollars in annual value - where the firm’s own data scientists knew big errors were being made and therefore it wasn’t likely to perform as promised. In this instance the fact that the issue was made transparent to the executive team meant they were able to investigate and de-risk the situation at a reasonably early stage.
In both instances a few themes came out:
The managers found themes that they would probably never have thought of asking about if they were developing a structured ‘traditional’ survey
That linking the feedback data with other data provided a lot of context and moved the comments from being random to something that needed investigating. You can think of this as highlighting a needle in the haystack
The comments themselves gave good insight into what the problem was, and what they needed to do to fix the problem.
6. WHAT ARE THREE KEY RECOMMENDATIONS YOU’D OFFER A HEAD OF HR/PEOPLE ANALYTICS LOOKING TO DEVELOP THEIR USE OF EMPLOYEE TEXT ANALYTICS?
Text analysis is one of those topics which is reasonably easy to start but difficult to get to the stage where it can be useful.
Lots of data scientists and IT folks will say they can do it but few will have the skills and knowledge to get to the part where it can be useful. You need to speak to some experts. They should be able to get you some results pretty quickly because they will already have the key pipelines built and refined.
Be willing to pick ‘easy’ projects first. I think anything that requires zoning - especially of documents which have no common structure - is something that you should avoid and / or find a specialist who specialises in that type of document. More specific text is easier to understand at a decent level than generic text
Ask yourself what you would want to find if you were analysing the data manually. Would you really want to rate each sentence on a score for sentiment? Would you want the sentences grouped into bigger themes? What would make those themes useful? Lots of people get influenced by what is possible e.g. sentiment or emotion scoring - rather than what they’d actually do if they were getting a skilled qualitative researcher to do the job. It’s almost always better, for example, to get sentiment from a structured quantitative question than it is by inferring it from text.

FIG 3: Example of a co-occurence network, which shows themes from individuals that are most likely to be mentioned together based on the probability of the co-occurence (Source: Andrew Marritt, Organization View)
7. WHERE CAN PEOPLE FIND OUT MORE ABOUT TEXT ANALYTICS?
Most of the writing I see on text analysis is quite technical. The discipline is changing so quickly that we find ourselves having to read large numbers of papers just to keep up. As the predominate techniques these days for text are based on deep learning models they require quite deep technical and mathematical understanding.
I’ve included some more business-focused articles in recent editions of our Empirical HR newsletter:
A podcast from Microsoft Research on machine translation. https://www.microsoft.com/en-us/research/blog/not-lost-in-translation-with-dr-arul-menezes/
A history of machine translation. Although it’s just focused on translation, the way translation has developed matches many of the other text analysis themes. http://vas3k.com/blog/machine_translation
A review of the recent history of natural language processing. Not easy without some knowledge but very thorough. http://blog.aylien.com/a-review-of-the-recent-history-of-natural-language-processing
Finally, if anyone has a large volume of text on a particular topic (e.g. 1000+ text answers to a specific open question) they should get in touch. Depending on the use-case we usually can turn-around a pilot in a few days.
THANK YOU, ANDREW
Thank you, Andrew for sharing your time, insights and considerable knowledge. Andrew’s weekly newsletter Empirical HR is always worth a read and covers people analytics, employee experience and many other topics as well as the latest in text analytics. I highly recommend you should subscribe.
Andrew can also be found on LinkedIn here, on Twitter @AndrewMarritt, and you can visit his company site Organization View where he also publishes a regular series of insightful articles.

ABOUT THE AUTHOR
David is a globally respected writer, speaker, conference chair, and executive consultant on people analytics, data-driven HR and the future of work. He helps HR practitioners and organisations leverage data and analytical thinking to drive positive business outcomes, improved performance, and enhance employee experience. Prior to launching his own consultancy business and taking up board advisor roles at Insight222 and TrustSphere, David was the Global Director of People Analytics Solutions at IBM Watson Talent. As such, David has extensive experience in helping organisations embark upon and accelerate their people analytics journeys.
UPCOMING SPEAKING ENGAGEMENTS
David will be chairing and/or speaking about people analytics, data-driven HR and the Nine Dimensions for Excellence in People Analytics model at the following events until the end of March 2019.
27-28 NOV – The HR Congress, Brussels
31 JAN - 1 FEB – People Analytics & Future of Work, San Francisco (Book before 31st October and use code DG300 before 30th November 2018 for a $300 discount)
5-6 FEB – HRD Summit, Birmingham
24-25 FEB - SHRM Tech EMEA, Dubai
19-20 MAR – UNLEASH, London
26-27 MAR – HR Core Lab - Leading with Talent Analytics, Barcelona